In 1996, Deep Blue played competitive Chess against world champion Garry Kasparov. In 2011, Watson beat Ken Jennings at Jeopardy. In 2016, AlphaGo played and beat Lee Sedol in Go. And in 2018, OpenAI Five played 2 games against professional Data 2 players, and the humans survived 2 very fun games. But in another year, I think that OpenAI Five will handily beat the best human Dota 2 teams.
(Disclaimer: I am neither a Dota 2 nor a Machine Learning expert, and I didn’t do much research for this blog post before diving into writing)
What is Dota 2?
For the unfamiliar, Dota 2 is 5-on-5 computer game, where each player controls a single, unique hero chosen from over 100 options. The game is played from a top-down view, and players click around to move, attack, and use abilities and items. Games typically last 20 minutes to one hour, and the players kill enemy minions and heroes to get better items and abilities and coordinate with their team to destroy the enemy base.
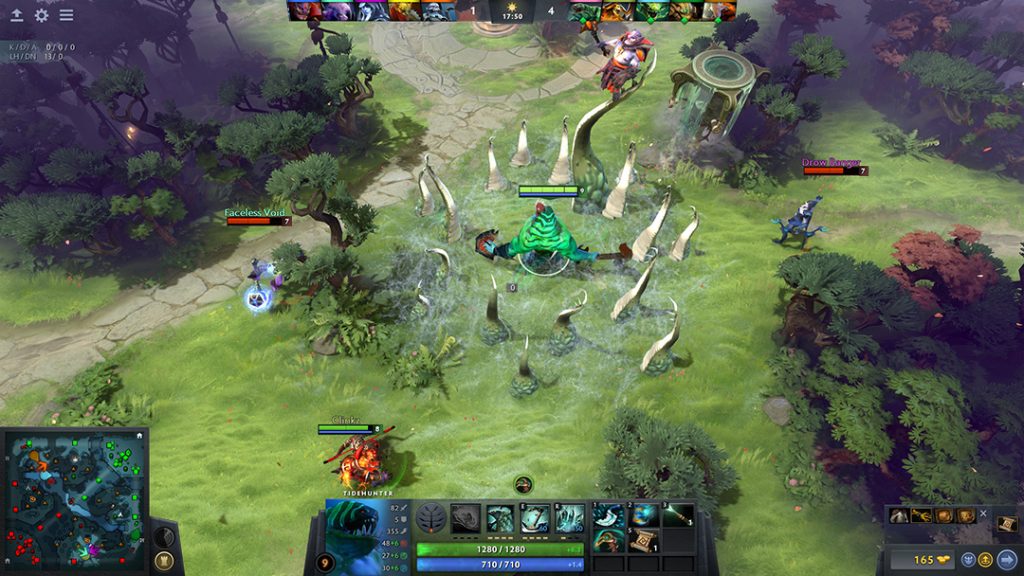
As the Dota 2 community says, “Game is hard.” Despite having played 493 hours and watched a ton of YouTube guides, I was ranked at about 50th percentile of players in a game that consistently has about a half-million concurrent players worldwide. The game requires:
- Quick reflexes. Some actions require < 100 ms response times. In comparison, games like Chess or Go are turn-based, so you have minutes to make a single decision
- Extensive game knowledge. According to some rough math, there are quadrillions of different hero combinations between the 2 teams. And then there are over 100 items you can buy.
- Great communication and coordination. Dota 2 is often played with strangers. On the internet. Who love trolling
Other Game-playing AIs
Historically, game-playing artificial intelligence (AI) belong to two categories. Both roughly follow approaches that humans might take.
First, you can try every possible way that the game could go and then pick the best option. This is similar to drawing a flow chart or imagining scenarios. For example, if you are driving into work rehearsing how you will ask your boss for a raise, you might think to yourself, “Well, I’m going to start with this, and he’s probably going to say that, so should I respond with this or that? Well, if I say that, then he’s going to say…” Humans can do it on a small scale, but it quickly becomes hard to remember all of the paths.
However, if you were a computer, you could branch out through all of those exponentially increasing possibilities quickly and store the best outcomes in memory. On top of this approach, researchers have optimized efficiently focusing only on the promising options and estimating the outcome, but it is still fundamentally just enumerating all possibilities.
Second, you can take human intelligence and just try to put that thinking into code. This is similar to traditional classroom or social learning. When you learned how to drive, someone told or showed you what to do, and you copied it. By memorization and pestering them with questions, you recreated that same knowledge in your mind. It takes more effort to translate ideas into code, but researchers can come up with extensive scripts to cover many cases.
What OpenAI Five is doing
But OpenAI Five isn’t doing either of these. The first approach is generally infeasible: in a real-time game with 10 players, the possibilities grow exponentially too quickly to evaluate all of them. The second approach just isn’t that good: the game comes with built-in “bots” for practice, and it’s difficult to capture the flexibility of human thinking for every situation.
Instead, OpenAI Five is using machine learning. Specifically, it is training bots to play Dota with a “Long Short-Term Memory recurrent neural network” for reinforcement learning through self-play. Let me break that down.
Machine learning is a very trendy set of techniques based on the idea that computers can learn by looking at tons of examples (this is “big data”) and using statistics to figure out what likely patterns are. For example, you might learn what the difference between a dog and a cat is by looking at a million examples of each and then generalizing to another example. The AI doesn’t even have to know what eyes or whiskers or teeth are: it’s just all patterns.
In reinforcement learning, an agent (i.e. an AI) learns to take an action to get some reward. It’s just like B.F. Skinner’s rats who learned to press a lever to get a food pellet. However, instead of learning a specific action and specific reward, the agent learns a “policy” where the best action depends on the situation. It can also learn to better estimate what the reward might be.
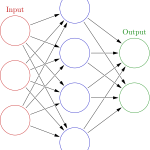
All of that learning is stored in a neural network. Rather than remembering the exact detail of the millions of examples it gets, the agent packs all of that together into a rough representation. Humans do something like this with words: if you asked me what I was looking at right now, I couldn’t perfectly make you see through my eyes. However, I could say, “I’m at home at my desk using my computer.” Although it leaves out a lot of detail, it is easy to say and keeps the important bits. Also, I could write that sentence down and come back a day later and create a very vivid and accurate picture in my head of what I was looking at. Neural networks can similarly pack complex data into a simple representations. (The process of re-creating the original data is related to “deep dreaming.”)
The LSTM and recurrent parts of neural networks are slightly trickier (they are deep learning techniques). The general idea is that you can integrate lots of different situations over time by feeding the data back into itself while also hanging onto past states as well. In other words, the same network would be responsible for representing Kevin at his desk and Kevin lying in bed. I could also give an even better idea of what Kevin in bed looks like if I knew whether I was just brushing my teeth or whether my alarm just went off. You could do this by making the neural network bigger and deeper, but it computationally becomes infeasible very quickly.
So to get that experience learning what possible actions can be taken and how it turns out, OpenAI Five was trained through self-play. This is like imagining what it would be like to fight (or more properly, perhaps play tennis against) yourself. OpenAI Five can just churn through games day and night to get years of experience by exploring and doing random stuff and seeing how it turns out. OpenAI pitched this as a big part of their methodology, but frankly, I think they were forced into it because they can’t realistically get enough continuous, quality training from anything else: scripted AIs aren’t smart enough, and humans play too slowly.
And that’s roughly how OpenAI Five learned to play Dota 2.
There are two more things I should mention. First, the bots play through an API, not a keyboard and mouse. It doesn’t click a mouse to move around or look at pixels on a screen to figure out what’s going on. It can just run a line of code to execute a command, and it gets the game state plugged straight into its algorithm.
Second, that’s all it knows about the game. No one told it that it should kill enemy heroes or even which way to walk to get into the fight. It learned all of that by doing random things in self-play and eventually connecting the idea of attacking enemies to winning more often than not.
I obviously glossed many details to how this works. And that is why OpenAI has many brilliant people working on it, and I’m just writing a blog post.
My Thoughts on the Games
So if you have followed me so far, I’m finally ready to get into the juicy, opinion part of this blog post.
I stumbled across the OpenAI Five Benchmark matches when they were live a few weeks ago. In it, OpenAI Five took 2 out of 3 games against 5 Dota personalities who are just a tick below the best professional players.
Watch OpenAI Five Benchmark from OpenAI on www.twitch.tv
This past weekend at The International, OpenAI Five played against 2 professional teams, and although the bots lost, they were fantastic, competitive games. Below are a mix of thoughts about Dota 2, AI, and philosophy.
A Mechanical Weakness?
Computers indisputably crush humans in reaction times. Humans have have squishy, sensory-driven and motor-executed abilities, whereas computers send 1s and 0s around like nobody’s business. In fact, this was one of the complaints and visible frustrations about Watson: even if they knew the answer, the humans couldn’t consistently buzz in faster than the computer.
Human Dota players work really hard on a technique called last-hitting. In Dota, you only get gold if you actually kill the minion, so it’s important to perfectly time your attack to get credit for that very last hit. It’s tough enough that the game had a built-in “last hit trainer,” and this video has over 600K views.
Surprisingly, OpenAI Five isn’t particularly good at last-hitting.
While the current version of OpenAI Five is weak at last-hitting (observing our test matches, the professional Dota commentator Blitz estimated it around median for Dota players), its objective prioritization matches a common professional strategy.
The blog post doesn’t lie about it, but it does continue with generous wording to explain how the AI prioritizes other aspects of the game over last-hitting.
It’s a non-fatal weakness, and although I’m sure the bots can improve, I wonder whether there is actually a ceiling on how good OpenAI Five can get at last-hitting given its generalized training regiment. Oddly, humans might actually be better at training this specific skill.
To become better players, humans prioritize last-hitting as a distinct skill from other decision-making in the game. We carve out practice time to work on that skill alone, and we actually are in a different mindset while in last-hitting in a game.
However, OpenAI Five doesn’t have that meta-reasoning about how it practices. It doesn’t choose to spend 25% of its time on one skill: the OpenAI team chose a generalized practice regimen (at least, this is my interpretation of what they have shared publicly), and all of these are integrated into a single model.
OpenAI Five is arguably doing the smart thing: maybe humans overestimate the importance of last-hitting and practice it too much if only because it’s a concept we can understand. Still, there’s no downside to OpenAI Five last-hitting better.
A Mechanical Advantage?
So maybe OpenAI Five isn’t great at last-hitting. However, it is phenomenal in team fights. Many of the most exciting moments in Dota 2 happen when all 10 players all show up in one place and duke it out with all of their abilities and items in a matter of seconds. Things can go very right and very wrong in surprising ways, such The Play.
Team fights require a lot of coordination, carefully positioning, and lightning fast reflexes. And OpenAI Five is phenomenal at it.
Watch OpenAI Five Benchmark from OpenAI on www.twitch.tv
It was so good that I couldn’t even pick only one example. Here’s a second example. Watch how Earthshaker (the bull on the right side of the screen) tries to jump into the middle of the fight but is instantly turned into a frog by OpenAI Five and rendered useless in the fight.
Of course, there’s a lot of other decision-making that leads up to the exact setup for the team fight, but in a perfectly fair, mirror team fight, I would bet on OpenAI Five and their mechanics every time.
OpenAI made a point to say that OpenAI Five is composed of 5 independent agents rather than one hive mind. In the panel, they clarified that it’s not as impressive as it might seem. They are using the same agent 5 times, and they also provide a sufficient feed of everything that the team sees on the map. Perhaps a more accurate explanation is not “it plays with 5 separate bots” but actually “imagine have 4 exact copies of yourself so you all think the same way, and all of you could see everything at the same time.” How much coordination would that require?
A Dota Turing test?
I recently watched The Imitation Game, a biopic that uses the Turing test as a framing device. The Turing test is a classic standard in AI: if you were conversing via text with 2 “people”, could you tell which one was the human and which one was the AI? We can extend this idea to Dota 2 as well: watching a game of Dota with humans on one side and bots on the other, could you tell which team was the humans?
It’s not a perfect test in this case because OpenAI Five is trying to win, not emulate human gameplay exactly. However, I think the Turing test is roughly given by humans along the way whenever we see the AI do something “dumb” that no human would ever do. For example, OpenAI Five sometimes place wards (items that let you see what’s going on in a certain area) right next to each other. The audience laughed when they pointed this out.
However, that might have been about the worst performance for OpenAI Five: it made some surprising choices, but it didn’t run to its death or spend a minute walking in circles. As one of the OpenAI team member said, it’s incredible that we’re even comparing the bots to humans and a real testament to their progress.
OpenAI’s Motivation
Humans tend to attribute cause-and-effect to how the world works. In real life, we come up with stories about why that other driver cut me off (because he’s a jerk) or why the ground is wet (because it rained last night). In a game of Dota 2, the casters often offer explanations for why a team made a certain decision. For example, Terrorblade buys the item Black King Bar because it makes him immune to being stunned so he can fight longer. Usually, the casters are right.
Out of habit, the casters made similar comments about why OpenAI Five made certain choices. For example, when Dota personality Purge was analyzing how OpenAI Five drafted (picked) the heroes for their team, he said:
As soon as the Shadow Fiend was picked, [OpenAI Five is] like, ‘Dumbasses, Shadow Fiend, Big Mistake’, and that was instantly when they felt really confident.
With a following explanation for how OpenAI Five would deal with the Shadow Fiend.
Is machine learning capable of discerning causation versus correlation? It’s a hard sell that AIs are doing causal reasoning, but frankly, humans are so bad at it that I’m not sure we can argue that we’re doing it either.
However, I would like to discuss how we explain cause-and-effect through sequences of concepts. When we describe something, we use words, which represent concepts that we share. If I say “chair” or “square” or “running”, you probably have a good idea of what I’m referring to. We have concepts in Dota 2, like “pushing” or “stacking” that are built on top of basic actions like “attack” or “buy.”
Although these concepts are generally shared by humans, they aren’t necessarily shared by AIs. Through learning and storing information in its neural network, OpenAI Five has come up with its own set of “concepts” that it combines to describe situations. As a simple (somewhat mathy) example,

if you were to describe this to another human, you might say, “a diagonal line from top left to bottom right” because you probably think of this world in ups and downs and lefts and rights. This description makes sense as a combination of those concepts. However, you (or maybe a computer) might learn to describe it as “a horizontal line if the world was rotated 45 degrees clockwise.” You get to the same result but get to it in different concepts.
And that’s what OpenAI Five is doing. It’s neural network has to condense the seemingly endless number of possible game situations in a (relatively) small set of numbers, so it comes up with concepts to represent it. Sometimes casters will say things like, “This game reminds me a lot of that EG-TL game from a tournament a few months ago.” OpenAI Five also looks at a game state as being a mixture of all of its past experience and could also say what games are “similar” based on the concepts it has.
Is OpenAI Five Thinking?
And all of these ideas above lead to my last, much fuzzier comment. Is OpenAI Five thinking?
Well, it depends on what you mean by thinking. I don’t think computers are ever going to think exactly like humans, and I frankly don’t think that would be desirable. We have plenty of humans to go around, and speaking from personal experience, we’re actually pretty stupid.
But OpenAI Five exhibits sophisticated behavior and learned. It interacted with humans in real-time. It came to this behavior through basic concepts that I doubt even its creators could explain in words. It is, of course, limited to this one task and couldn’t have a conversation with you, but it is impressive.
My point is that we should judge its thinking based its output, not how it thinks. It was made by humans, and we can (mostly) explain how it does what it does, but that isn’t a knock against it. Although we can introspect, we don’t exactly understand how the brain works, but if we did understand (whether it’s all biology or if there’s some spiritual aspect), it doesn’t mean that we’re not thinking anymore. Thinking and intelligence can come about in many ways, and it’s fascinating to develop more ways that are different than our own.
Last Thoughts
Despite my criticisms of OpenAI Five’s shortcomings and nitpicks about what OpenAI has shared, I’m very impressed by the progress so far. Before seeing it, I could have offered a dozen reasons why Dota 2 is too hard for AI, but OpenAI worked hard and should be proud of their progress.
I made the bold statement at the beginning that OpenAI Five will wipe the map with humans in another year. Given its rapid progress, I see no reason for its performance to be capped by human performance. We have no magical ceiling that prevents OpenAI Five from figuring out even bigger players or subtle optimizations that humans haven’t figured out.
So I’ll keep cheering for The Humans because it’s fun while we still have a chance. I’m excited to see what OpenAI accomplishes next, not only in Dota 2, but in applying these techniques to other problems.
References
On top of the links I sprinkled above, here are the really important OpenAI blog posts: